
Una introducción a los sistemas de recomendación y los desafíos de la personalización de la experiencia de juego
POR FEDERICO SCHEFFLER, DATA SCIENTIST EN ETERMAX
La mayoría de los usuarios de plataformas digitales están expuestos, consciente o inconscientemente, a sistemas de recomendaciones para personalización del contenido. Los sistemas de recomendación engloban al conjunto de herramientas usadas para segmentar usuarios y ofrecerles recomendaciones de productos o contenido en base a sus preferencias. Hoy en día la personalización de contenido abarca desde el ordenamiento del feed de redes sociales como Instagram o TikTok [1,2] hasta playlists editoriales de Spotify que varían sutilmente de contenido para cada usuario [3]. El uso de sistemas de recomendación de contenido reduce la sobrecarga de información a la que se expone el usuario, brindando una experiencia acotada pero mucho más personalizada.
En este artículo, haremos una introducción a los algoritmos de recomendación, veremos el tipo de información que necesitamos para construir un modelo de recomendación y describiremos brevemente cómo podríamos utilizarlos en juegos como Preguntados para organizar el servidor de contenido. Tomaremos como ejemplo la aplicación de estos sistemas al juego Preguntados Aventura.
Datos, datos, datos.
Los sistemas de recomendación utilizan algoritmos de Machine Learning que aprovechan el feedback del usuario ante distintos ítems o piezas de contenido para identificar posibles preferencias. En el caso de juegos con preguntas temáticas como Preguntados Aventura, resulta de interés encontrar las temáticas o tópicos que podrían ser más relevantes para los jugadores en base a su experiencia de juego.
La pieza más básica e indispensable para poner en marcha un sistema de recomendación es la disponibilidad de datos de los usuarios. No son los algoritmos del estado del arte, ni grandes equipos de procesamiento distribuido, sino los datos que permiten identificar las preferencias de los usuarios. Existen diferentes formas de recolectar las señales de preferencia, o feedback, de los usuarios. Según el tipo de señal podemos clasificarlas en:
Feedback Explícito: Se obtiene cuando el usuario demuestra de manera directa su preferencia por un ítem o pieza de contenido. Este tipo de feedback es usual en servicios en los que el usuario puede dar like o dislike a los ítems, o bien aquellos en los que el usuario pone una calificación a partir de una escala a los ítems que consumió en el pasado. No obstante, muchos usuarios no dan feedback explícito a menos de que se sientan altamente satisfechos o disconformes. Por esto, el feedback explícito no suele estar disponible masivamente ni suele ser la primera opción para muchas aplicaciones.
Feedback Implícito: Surge de la observación de las acciones e interacciones del usuario. Incluye señales como el historial de ítems vistos y consumidos, el tiempo que el usuario pasó interactuando con una pieza de contenido, el número de veces que eligió ítems de determinada categoría, entre otros. Este tipo de feedback no requiere participación extra del usuario, sino que se construye a partir de una cuidadosa selección de las señales disponibles.
Nuestros juegos de trivia no son la excepción a la regla y la tasa de uso de las features de likeo es muy baja. Sin embargo, contamos con mucha información de interacciones entre usuarios y preguntas de trivia. Con el fin de identificar y cuantificar la afinidad de los usuarios con los tópicos construímos un índice de afinidad que tiene en cuenta para cada usuario-tópico:
- Cantidad de preguntas respondidas
- Tasa de aciertos
- Dificultad media de las preguntas respondidas
- Cantidad de preguntas de trivia por tópico
- Popularidad de las preguntas
Este índice nos permite inferir las preferencias de usuario, en base a su conocimiento y genera muchas oportunidades para personalizar su experiencia.
Generando recomendaciones con filtro colaborativo
Existen dos grandes enfoques, combinables, a la hora de generar recomendaciones: Filtro basado en contenido y filtro colaborativo.
En los filtros basados en contenido, se construye un perfil de los ítems con sus principales características y un perfil de usuario basado en los ítems en los que se observó feedback positivo. Con esta información, a cada usuario se le recomendarán ítems parecidos a los que les gustó en el pasado. Este tipo de recomendadores son muy efectivos para entender las preferencias del usuario y recomendar ítems similares a los que mostró afinidad. Sin embargo, no es el más adecuado para recomendar ítems o contenido muy diferente a los que el usuario consumió. Particularmente, en juegos como Preguntados el usuario responde preguntas al azar y debemos identificar contenido que podría ser de su interés aún antes de que responda preguntas de esa temática. Por este motivo no optamos por un filtro basado en contenido para una primera iteración de un recomendador.
Los filtros colaborativos, por otro lado, parten de la premisa de que podemos identificar los ítems que podrían ser del agrado de un usuario a partir de las preferencias de otros usuarios. Particularmente, se recopilan las preferencias pasadas de un usuario y se construyen recomendaciones basadas en los ítems que hayan elegido otros usuarios que compartan los mismos intereses. En el caso de los juegos de trivia podríamos identificar los posibles tópicos de interés para un usuario nuevo en base a los tópicos que le gustaron a usuarios similares. Por ejemplo, a un usuario que demostró afinidad por preguntas del Antiguo Egipto se le podrían recomendar con certeza tópicos a los que muchos otros usuarios afines al Antiguo Egipto también han demostrado interés. A su vez, se pueden recomendar tópicos en los que sólo algunos de los usuarios afines a la temática egipcia mostraron interés, como por ejemplo Gatitos o Banderas del Mundo.
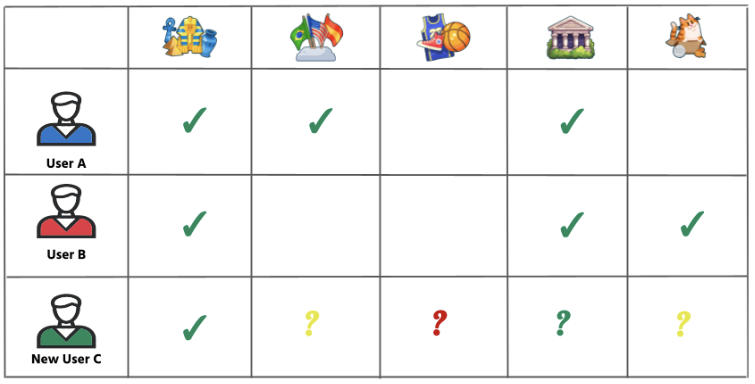
Una de las principales ventajas de las recomendaciones por filtrado colaborativo es que permiten anticipar las preferencias del usuario por ítems muy distintos a los que usualmente consume, facilitando y en ocasiones forzando la exploración guiada. Una ventaja adicional es que no necesitamos contar con conocimiento a priori de las posibles preferencias del usuario.
En la práctica, las señales de afinidad no siempre están definidas como “Gusta”/”No me gusta”. Para nuestro recomendador de tópicos, el feedback viene bajo la forma del score de afinidad descrito anteriormente. En general, la mayoría de los usuarios solo interactúa con un pequeño grupo de ítems, por lo que la tabla o matriz de interacciones usuario-item suele estar mayormente vacía. En términos puramente matemáticos, la matriz de interacciones toma la forma de una matriz esparza de grandes dimensiones, proporcional al número de usuarios e ítems.
Existen varios algoritmos para obtener recomendaciones por filtrado colaborativo a partir de una matriz de interacciones. En los algoritmos basados en modelos se busca representar las complejas interacciones usuario-producto mediante matrices de menor dimensión. Mediante métodos de factorización matricial [4], se busca comprimir la información de la matriz de interacciones en matrices de menor tamaño que preserven las características más relevantes. De esta manera, se pueden representar patrones de afinidad de cientos de miles de usuarios e ítems a un costo computacional reducido.
En nuestras aplicaciones buscamos generar recomendaciones de contenido para toda la base de usuarios activos, siempre y cuando fuese posible identificar tópicos afines a estos usuarios. El volumen de ítems está en el orden de varios cientos, por lo que no es computacionalmente costoso poner en producción un sistema de recomendaciones.
Validando las recomendaciones
Ante la falta de feedback explícito de los usuarios con respecto al contenido que le gusta, es difícil evaluar la performance de un recomendador de contenido. En términos clásicos de precisión y recall, se debería utilizar la propia métrica de afinidad que nosotros mismos definimos anteriormente, con el riesgo de sobreajustar nuestras recomendaciones a este criterio. Sin embargo, el uso de filtros colaborativos permite al menos en primera instancia corroborar que el contenido recomendado tenga sentido en términos temáticos.
Hay muchos interrogantes que no pueden ser respondidos a través de pruebas con los datos de entrenamiento. ¿El usuario disfruta de responder preguntas de temática similar? ¿Estamos mejorando la experiencia del usuario a mediano/largo plazo? ¿Cómo estamos impactando la economía del juego y del negocio? Sólo podremos corroborar que la personalización de contenido mejora la experiencia del usuario y no afecta negativamente al negocio mediante pruebas de A/B [5]. Afortunadamente, nuestras aplicaciones cuentan con un volúmen saludable de usuarios que permitieron llevar adelante pruebas de A/B antes de implementar las features de personalización a gran escala. La propuesta de servidor de tópicos personalizados en la aplicación Preguntados Aventura permitió aumentar la retención de usuarios a día 7 en aproximadamente un 6%, sin impactar negativamente en las métricas de recaudación.
Próximos desafíos
En las plataformas de e-commerce o de streaming, los usuarios buscan y eligen el contenido o los ítems que desean consumir. En los juegos de trivia de etermax, en la mayoría de los modos de juego el usuario debe responder preguntas al azar. ¡Es una competencia después de todo! El usuario entonces pasa a tener un rol de consumidor pasivo y solo reacciona al contenido que se le sirve. Es de gran importancia identificar e interpretar las señales de feedback implícito que provee el usuario para construir mejores modelos de afinidad con el contenido.
Por otro lado, los métodos basados en filtro colaborativo presentan algunas dificultades a la hora de realizar predicciones para usuarios nuevos. Este es el problema del arranque en frío, o cold start problem. En la industria de juegos, la tasa de retención es relativamente baja por lo que es de suma importancia generar una buena primera impresión, y hacerlo rápido. Debido a la amplia variedad temática de preguntas en los Preguntados y Preguntados Aventura, es necesario optimizar la experiencia inicial para asegurar que el usuario sea expuesto a una amplia variedad de temáticas.
Otro desafío que surge es cómo llevar la personalización al siguiente nivel. ¿Cómo podemos personalizar el set de preguntas que responde el usuario en una partida de trivia? Extrapolar las recomendaciones de un par de cientos de tópicos a cientos de miles de preguntas traería varios desafíos técnicos. A nivel juego además es necesario balancear la personalización temática con la dificultad de la trivia para asegurar que nuestros juegos provean un desafío constante.
Esperamos compartir durante este año cómo encaramos estos desafíos y los avances en nuestros esfuerzos de personalización de contenido.
[1] https://newsroom.tiktok.com/en-us/how-tiktok-recommends-videos-for-you
[2] https://about.instagram.com/blog/tips-and-tricks/control-your-instagram-feed
[5] https://medium.com/etermax-technology/ab-testing-for-better-decision-making-12b56bd9e5e1